Mit Python-tesseract können ganz einfach Texte in Grafiken erkannt und ausgegeben werden. Möglich macht dies Google’s Tesseract-OCR (Optical Character Recognition), eine freie Software zur Texterkennung. Dank Sprachmodelle, wie beispielsweise Wörterbücher, ist so auch die deutsche Sprache für Tesseract kein Problem. Wie man mithilfe von einem kleine Python-Programm unter Windows ganz leicht Texte aus Bildern liest, möchte ich nachfolgend zeigen.
Inhaltsverzeichnis
Tesseract unter Windows installieren
Eigentlich ist Tesseract für Linux gedacht, dank der Universität Mannheim gibt es aber auch einen Windows-Installer. Die Universität Mannheim nutzt Tesseract zur Verarbeitung von historischen deutschen Zeitungen. Den Windows-Installer findet man unter https://github.com/UB-Mannheim/tesseract/wiki
Einfach herunterladen und installieren. Der Installationspfad wird später noch benötigt.
Image und pytesseract installieren
Da die Module image und pytesseract importiert werden, müssen sie, sofern sie noch nicht vorhanden sind, erst noch per pip installiert werden. Dies geht ganz einfach mit dem nachfolgenden Befehl:
pip install Image
pip install pytesseractNun könnte man reintheoretisch schon loslegen, die deutsche Sprache wird aber noch nicht unterstützt.
Deutsches Sprachpaket installieren
Sofern nicht schon bei der Installation von Tesseract geschehen, muss noch das deutsche Sprachpaket installiert werden. Dafür muss man die Deutsche Trainig Data erst herunterladen und in das ‚tessdata‘-Verzeichnis, z.B. unter „C:\Program Files (x86)\Tesseract-OCR\tessdata“ kopieren. Die Trainings-Data für alle Sprachen findet man unter: https://github.com/tesseract-ocr/tesseract/wiki/Data-Files Hier einfach die deu.traineddata herunterladen und ins entsprechende Verzeichnis kopieren.
Kleines Python-Programm zur Texterkennung
Nun kann man auch schon loslegen. Im nachfolgenden kleinen Beispielprogramm, wird einmal das englische Standard-Wörterbuch genutzt, bei der zweiten Ausgabe wird hingegen explizit das deutsche Wörterbuch genutzt:
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
# Hier muss der Installationspfad von tesseract angegeben werden
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract'
print("Text auf dem Bild lautet ...")
print("... mit dem englischen Wörterbuch:")
# Normale Textausgabe (sucht nach englischen Woertern) aus dem Bild test.png
print(pytesseract.image_to_string(Image.open('python-texterkennung.jpg')))
print("... mit dem deutschen Wörterbuch:")
# Sucht explizit nach deutschen Woertern, beispielsweise wichtig bei Text mit Umlauten
print(pytesseract.image_to_string(Image.open('python-texterkennung.jpg'), lang='deu'))Beispiel-Ausgabe
Nachfolgend eine Beispielausgabe mit dem oberen Code und dem Bild das ich oben in der Einleitung des Artikels verwendet habe:
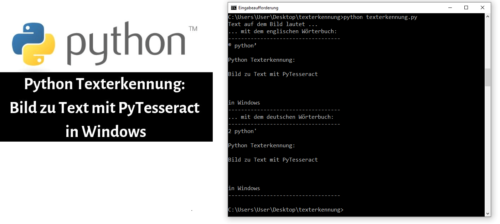
Man beachte bei der Ausgabe, dass das Programm nicht nur den reinen Text erkannt hat, sondern auch noch den Text im Python-Logo. So lässt sich die etwas kryptische Ausgabe „2 python'“ auf das Logo zurückführen.
Text aus PDF herauslesen mit Python
Auch aus PDFs kann man mit Tesseract und Python den Text auslesen. Hierbei muss einfach erst einmal das PDF via dem Modul pdf2image in ein Bild umgewandelt werden. Möchte man beispielsweise die erste Seite eines PDFs zu einem Bild umwandeln, dann reicht folgender Code:
from pdf2image import convert_from_path
bild = convert_from_path("test.pdf")[0]
bild.save("test.png", "png")Weiter Infos gibt es unter: https://github.com/madmaze/pytesseract
Ähnliche Themen:
läuft bei mir auch unter MacOSX, wenn man die Zeile
pytesseract.pytesseract.tesseract_cmd = r’C:\Program Files (x86)\Tesseract-OCR\tesseract‘
deaktiviert
bild = convert_from_path(„test.pdf“)[0] funktioniert nicht.
pdf2image.exceptions.PDFInfoNotInstalledError: Unable to get page count. Is poppler installed and in PATH?
Anscheinend funktioniert diese Lösung nur unter Linux